Modelling Workflows With Finite State Machines in .NET
Introduction #
Before I introduce the concept of finite state machines, I’d like to first describe how a workflow, process, sequence of steps or complex UI might typically be implemented.
Imagine a document which needs to be “approved” before it can be sent to a customer - to check for anything from grammar and spelling mistakes to agreed services and prices. Then, imagine that once it’s been approved it’s then sent to the customer. The customer has to approve, reject, or request changes. Whichever they choose, the document is then sent back to the approver for further review. This goes on until the document is complete and every stakeholder has approved it.
The problem #
Let’s do some approximate maths to figure out how many steps, or states, this seemingly simple workflow would have.
- Before it’s either approved or sent to the customer it’s obviously in some kind of state. I’ll call this “draft”.
- It has to be approved or changes requested by the internal stakeholders.
- If changes have been requested, then that branches into its own set of states.
- The customer approves the document.
- The customer rejects the document.
- The legal team approves the document.
- and so on…
That’s already 6+ states, but there’s a lot more. The more states, the more complex the workflow. If we try model this workflow in code, we’ll soon end up with dozens if not hundreds of flags to represent the “current” state. That doesn’t take into account states with extra information like Change request: "change the title". Further still that doesn’t even take into account the number of flags that can be set concurrently.
- No clear separation between “states” and “steps” - a number of steps can lead to the same state, for example.
- A new feature could impact the code greatly - or maybe not at all. There’s no easy way of knowing.
- Each new state increases the number of flag permutations
- Even with unit testing the code is still complex and hard to maintain
- Bugs creep in and refactoring gets harder as more states are added
- Isn’t following the making illegal state unpresentable concept - it’s too easy for invalid states to be made accidentally possible leading to flaws in the business logic. If we can shift as much as possible into the type system we should.
- All of these factors soon lead to the situation where the code no longer matches the domain
In whichever language you use, you’ll end up with something that looks like this.
// I'm using C# records for this example.public record Document( bool IsInDraft, bool HasBeenReviewedByLegal bool IsApproved, bool IsRejected, bool IsSentToCustomer, ... bool Is💩);if (document.IsInDraft){ if (!document.HasBeenReviewedByLegal) { ... } else if (document.IsSentToCustomer && document.Approved || document.Rejected) { ... } else { ... }}...This seems innocent and simple enough. But as you’ve probably seen like I have; this type of code can often become that part of the codebase that spans hundreds or thousands of lines long and probably all in a single file too. That part of a codebase is often the part developers do not want to look at or work on. Developers might even try circumventing it by writing new logic in another part of the codebase thus compounding the issue even further.
A solution #
There are potentially countless solutions but the solution I’m going to propose to this “document workflow” problem is to use a finite state machine. First, a formal definition of a finite state machine:
A finite-state machine (FSM) or finite-state automaton (FSA, plural: automata), finite automaton, or simply a state machine, is a mathematical model of computation. It is an abstract machine that can be in exactly one of a finite number of states at any given time. The FSM can change from one state to another in response to some inputs; the change from one state to another is called a transition. An FSM is defined by a list of its states, its initial state, and the inputs that trigger each transition.
That’s a lot to take in! FSM’s are a “universal” concept that can be used practically anywhere and in particular maths, electronic engineering/embedded systems, science, and software engineering. In this particular case we’re using it to model a “document workflow” in software to replace needlessly complex and nested logical states. It’s also worth pointing out that FSM’s can be used to model a wide range of domains. For example, user interfaces can be implemented with them too, for exactly the same reasons I previously listed; to manage complexity and make states and transitions more explicit.
Remember, the first step in creating an FSM is figuring out the states and transitions that are needed. This step alone is an excellent opportunity to get business analysts/domain experts/product team/whomever to weigh in. This will also force some up-front design to make sure the code correctly matches the domain.
Implementation #
I’ll be using the stateless library to create the FSM as I use this library in several projects. Of course, creating it from scratch would be an interesting exercise too.
Create state machines and lightweight state machine-based workflows directly in .NET code.
— README

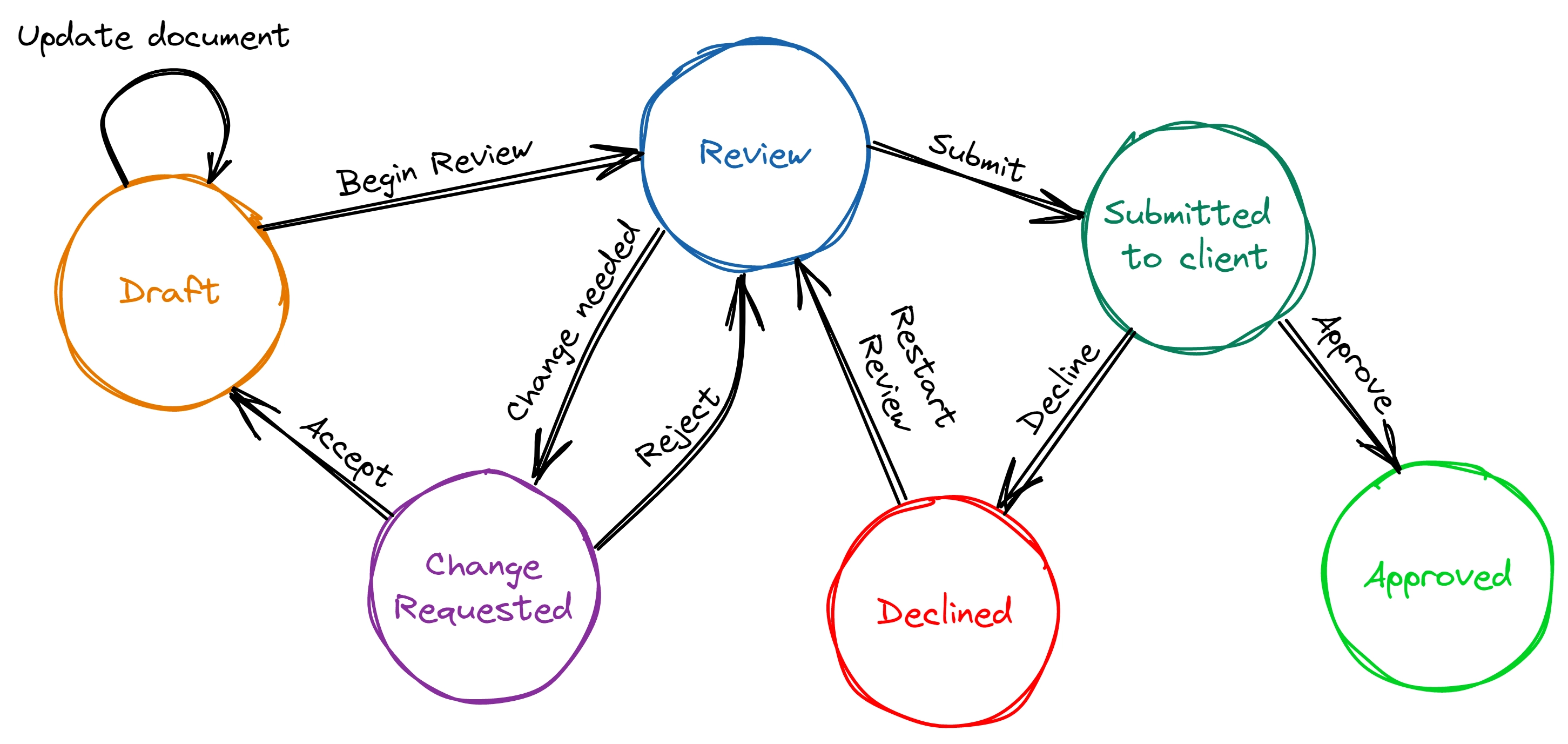
I’ve created the FSM for the document workflow example in diagram form. I’ll now create it in code form. The stateless library recommends keeping enums for the states and transitions inside the same class using the FSM but that’s only a recommendation.
Creating the State and Triggers enums #
using Stateless;
namespace DocumentWorkflow.FiniteStateMachine{ public class Document { private enum State { Draft, Review, ChangesRequested, SubmittedToClient, Approved, Declined }
private enum Triggers { UpdateDocument, BeginReview, ChangedNeeded, Accept, Reject, Submit, Decline, RestartReview, Approve, } }}Configuring the states and transitions #
Next is the setup of the FSM. I need to configure the states and transitions and how they relate. We can also hook into the FSM in order to execute business logic. I’ll cover more on that in the next section.
namespace DocumentWorkflow.FiniteStateMachine{ public class Document { private readonly StateMachine<State, Triggers> machine;
private readonly StateMachine<State, Triggers>.TriggerWithParameters<string> changedNeededParameters;
public Document() { // We can create the FSM with state stored in a file, DB, ORM wherever. In that case we'd need to create a factory // so the constructor isn't doing long/async work. //machine = new StateMachine<State, Triggers>(() => state, s => state = s);
machine = new StateMachine<State, Triggers>(State.Draft);
machine.Configure(State.Draft) .PermitReentry(Triggers.UpdateDocument) .Permit(Triggers.BeginReview, State.Review) .OnEntryAsync(OnDraftEntryAsync) .OnExitAsync(OnDraftExitAsync);
changedNeededParameters = machine.SetTriggerParameters<string>(Triggers.ChangedNeeded);
machine.Configure(State.Review) .Permit(Triggers.ChangedNeeded, State.ChangesRequested) .Permit(Triggers.Submit, State.SubmittedToClient) .OnEntryAsync(OnReviewEntryAsync) .OnExitAsync(OnReviewExitAsync);
machine.Configure(State.ChangesRequested) .Permit(Triggers.Reject, State.Review) .Permit(Triggers.Accept, State.Draft) .OnEntryAsync(OnChangesRequestedEntryAsync) .OnExitAsync(OnChangesRequestedExitAsync);
machine.Configure(State.SubmittedToClient) .Permit(Triggers.Approve, State.Approved) .Permit(Triggers.Decline, State.Declined) .OnEntryAsync(OnSubmittedToClientEnterAsync) .OnExitAsync(OnSubmittedToClientExitAsync);
machine.Configure(State.Declined) .Permit(Triggers.RestartReview, State.Review) .OnEntryAsync(OnDeclinedEnterAsync) .OnExitAsync(OnDeclinedExitAsync);
machine.Configure(State.Approved) .OnEntryAsync(OnApprovedEnter); } }}Creating the actions to execute business logic #
Now the actions mentioned previously need to be configured. The library makes use of Func to enable this. In this particular workflow we’re creating, I’ve opted to keep the actions very simple for demonstration purposes. Imagine a hypothetical NotificationService that takes care of sending FSM updates to the rest of the system. Potentially each of these actions could instead have lots of business logic.
However, I prefer to work on decoupled systems that make use of concepts like event driven architecture, DDD, message queues, Mediatr and the like.
With that in mind, this approach could work very well for such a system. Or you might prefer to keep things more localised and have more of the business logic in the actions. Potentially some combination of the two. “It depends” as the saying goes.
namespace DocumentWorkflow.FiniteStateMachine{ public class Document { private async Task OnDraftEntryAsync() { await notificationService.SendUpdateAsync(Priority.Verbose, "The proposal is now in the draft stage"); }
private async Task OnDraftExitAsync() { await notificationService.SendUpdateAsync(Priority.Verbose, "The proposal has now left the draft stage"); }
private async Task OnReviewEntryAsync() { await notificationService.SendUpdateAsync(Priority.Verbose, "The proposal is now in the review stage"); }
private async Task OnReviewExitAsync() { await notificationService.SendUpdateAsync(Priority.Verbose, "The proposal has now left the review stage"); }
// continued }}Defining a public API #
So far, all the code has been private to the Document class. We need to create the public facing API for the document in order to trigger transitions. At first there appears to be some duplication between the public API and the private implementation. But, upon closer inspection these are two different things. Remember, we created the FSM and configured its states and transitions. We then created the actions that will be called when the FSM transitions. This next part is specifically how an instance of Document is used.
namespace DocumentWorkflow.FiniteStateMachine{ public class Document { public async Task UpdateDocumentAsync() => await machine.FireAsync(Triggers.UpdateDocument);
public async Task BeginReviewAsync() => await machine.FireAsync(Triggers.BeginReview);
public async Task MakeChangeAsync(string change) => await machine.FireAsync(changedNeededParameters, change);
public async Task AcceptAsync() => await machine.FireAsync(Triggers.Accept);
public async Task RejectAsync() => await machine.FireAsync(Triggers.Reject);
public async Task SubmitAsync() => await machine.FireAsync(Triggers.Submit);
public async Task RestartReviewAsync() => await machine.FireAsync(Triggers.RestartReview);
public async Task ApproveAsync() => await machine.FireAsync(Triggers.Approve);
public async Task DeclineAsync() => await machine.FireAsync(Triggers.Decline); }}That’s a lot of code to take in. I’ll break it down into smaller pieces while expanding on the many features of the library.
machine = new StateMachine<State, Triggers>(State.Draft);
machine.Configure(State.Draft) .PermitReentry(Triggers.UpdateDocument) .Permit(Triggers.BeginReview, State.Review) .OnEntryAsync(OnDraftEntryAsync) .OnExitAsync(OnDraftExitAsync);- The FSM instance is created and assigned to the private readonly field
machine Draftis the default state as this is a natural starting point for a document- A user updates a document as it’s being written so we allow re-entry from the draft state to the draft state - this would have the content to change as it’s argument if our example document had any content
- Permit the FSM to transition to the
Reviewstate when theBeginReviewtransition is triggered - The entry and exit actions previously discussed are configured
That of course is only the configuration for one of the available states. Extrapolating how the other states are configured should be straightforward.
Conditionally executing code depending on the previous state #
Although I didn’t need to make use of this functionality for this relatively simple document workflow example, I’ve included it here for completeness. It’s definitely an extremely useful feature to have. Previously I mentioned how it’s common for a number of transitions to lead to a single state. Consider a more complex Review part of the workflow. It could be extremely convenient or maybe even essential to know the previous state that the was just transitioned away from.
That would look something like the following:
machine.Configure(State.Review) .Permit(Triggers.ChangedNeeded, State.ChangesRequested) .Permit(Triggers.Submit, State.SubmittedToClient) .OnEntryFromAsync(Triggers.Decline, OnEntryFromDeclinedAsync) .OnEntryAsync(OnReviewEntryAsync) .OnExitAsync(OnReviewExitAsync);Handling invalid transitions #
So far, we’ve built a FSM to model a document workflow. At the start of the article many problems were described relating to the complexity of building workflows or other business logic with lots of conditionals. One of those was:
Isn’t following the making illegal state unpresentable concept - it’s too easy for invalid states to be made accidentally possible leading to flaws in the business logic. If we can shift as much as possible into the type system we should.
If we’d implemented this workflow “manually” then we’d have growing complexity and the possibility that certain constraints would be missed. As we did some upfront design and creating a diagram that was then implemented in code, let’s see what happens if we try to execute an invalid transition.
var document = new Document();
// Let's try be sneaky and submit the document to the client before it's even been reviewed!await document.SubmitAsync();System.InvalidOperationException HResult=0x80131509 Message=No valid leaving transitions are permitted from state 'Draft' for trigger 'Submit'. Consider ignoring the trigger. Source=Stateless StackTrace: at Stateless.StateMachine`2.DefaultUnhandledTriggerAction(TState state, TTrigger trigger, ICollection`1 unmetGuardConditions) at Stateless.StateMachine`2.UnhandledTriggerAction.Sync.Execute(TState state, TTrigger trigger, ICollection`1 unmetGuards) at Stateless.StateMachine`2.UnhandledTriggerAction.Sync.ExecuteAsync(TState state, TTrigger trigger, ICollection`1 unmetGuards) ...An exception! That’s a good start. But being good developers we shouldn’t be doing exception-driven development. This should be modelled with a construct from functional programming: monads. That’s a topic for another article.
Stateless provides a way of centrally handling invalid transitions:
machine.OnUnhandledTrigger((state, trigger) => notificationService.SendUpdateAsync( Priority.Blocking, $"Document is currently in \"{state}\". There are no valid exit transitions from this stage for trigger \"{trigger}\"."));
// Proposal is currently in "Draft". There are no valid exit transitions from this stage for trigger "Submit".Other capabilities of the library #
- Hierarchical states - This allows for substate. In this example
Draft,ReviewandChangesRequestedcould be substates ofEdit. - Internal Transitions - This is for the scenario where a transition to the same state needs to be handled. The exit and entry actions are not called, and the state does not change.
- Guard clauses -
PermitIfandPermitIfAsyncare the same as theirPermitandPermitAsynccounterparts but with the ability to permit or reject a transition based on the arguments. For example, to ensure the change to the document was more than an empty string. - External State Storage - This ability was hinted at in the code. Persisting and loading the state from an external source allows for greater flexibility. The state of our document workflow could be saved anywhere.
Introspection and exporting to DOT graph format #
We might have the need to get a list of available transitions for a given state. This is available via the StateMachine.PermittedTriggers property. To get the state configuration we can use StateMachine.GetInfo().
Extending on this we can generate a DOT. Here is the document workflow visualised with a Graphviz enabled site.
string graph = UmlDotGraph.Format(document.GetInfo());
// Our document workflow becomes:digraph { compound=true; node [shape=Mrecord] rankdir="LR" "Draft" [label="Draft|entry / OnDraftEntryAsync\nexit / OnDraftExitAsync"]; "Review" [label="Review"];...
I’ve found both of these abilities to be great aids while debugging. Being able to get a list of states and transitions can also be used to drive a UI.
Unit testing #
Unit testing becomes a matter of simply creating an instance of the finite state machine and asserting that valid transitions for a given state can occur correctly while also asserting that invalid transitions cannot occur.
For example, consider the following code from another one of my projects:
[Theory, AutoData]public void ShouldNotCauseAnySideEffectsWhenTransitioningFromOffToOff(TestTimer timer){ var logger = Substitute.For<MockLogger<FiniteStateMachinePumpController>>(); var pumpInterface = Substitute.For<IPumpInterface>(); var pumpController = new FiniteStateMachinePumpController(null, timer, pumpInterface, 1);
pumpController.TurnOff(); pumpController.TurnOff();
pumpInterface.DidNotReceive().SetSpeed(Arg.Any<int>(), Arg.Any<double>());}Conclusion #
I’ve covered a lot in this article. We have successfully implemented a document workflow.
- Explained the problems of complex and deeply nested conditional code that is common as it needs to match a domain model
- Introduced the concept of a state machine and how it can be a solution to both reducing complexity and making certain states unrepresentable thus reducing the ability for bugs to be introduced
- Differentiated between the public API and the internal implementation details of a document
- Created a diagram of the workflow and translated it into code while highlighting the need for business analysts/domain experts to weigh in
- Handled invalid transitions with a centralised error handling mechanism
- Gave an example of how-to unit test code using the FSM
I hope this article has helped you to understand the disadvantages of complex and deeply nested conditional code and has brought a new perspective on how to write code that is easier to understand and maintain. Remember, it’s a “universal” concept that can be applied to a wide range of problem areas you’ll write code for. Happy finite-state-machine-ing!